Picture this: You’ve just finished all 21 Quantitative Reasoning questions with two minutes to spare. As you scan back through your responses, that nagging doubt creeps in. Question 12 looks suspicious. Question 15 feels too straightforward. Question 18… you’re second-guessing the approach entirely.
Here’s what thousands of test-takers don’t realize: data shows that, if you’re reviewing questions after position 9, three out of four times you change an answer, you are not likely to improve your score.
⭐ Key Insights from This GMAT Review Analysis:
This comprehensive analysis of review patterns across thousands of GMAT attempts reveals a startling truth that flips conventional test-taking wisdom on its head:
- Why do 75% of review changes after Question 9 fail to improve scores?
- What makes Questions 1-8 the “golden zone” for productive review?
- How does the GMAT’s adaptive algorithm create this dramatic effectiveness shift?
This analysis provides data-driven insights to help you maximize your review strategy and avoid common timing mistakes.
⭐MASTER STRATEGIC REVIEW TIMING
Discover the data-driven approach that separates high scorers from everyone else. Access our comprehensive GMAT timing strategies, adaptive practice tests, and proven review methodologies.
This isn’t about time management—you’ve “likely” already finished the section. This isn’t about panic—you’re calmly reviewing with time remaining. This is about a hidden mathematical reality that separates high scorers from everyone else: knowing when your first instinct is smarter than your second guess.
Recent analysis of review patterns across thousands of GMAT attempts reveals a startling truth that flips conventional test-taking wisdom on its head. The same mental process that helps students improve their scores 70% of the time in early questions becomes virtually useless—and sometimes harmful—after Question 9.
Most remarkably, students who achieve breakthrough (Q86+) scores don’t just solve problems better—they know when to stop solving problems. They focus on building ability rather than worrying about timing – because as this data reinforces, simply throwing more time on questions does not help you answer questions beyond your “current ability”.
The Data Reveals: Four Critical Patterns in QR Review Behavior
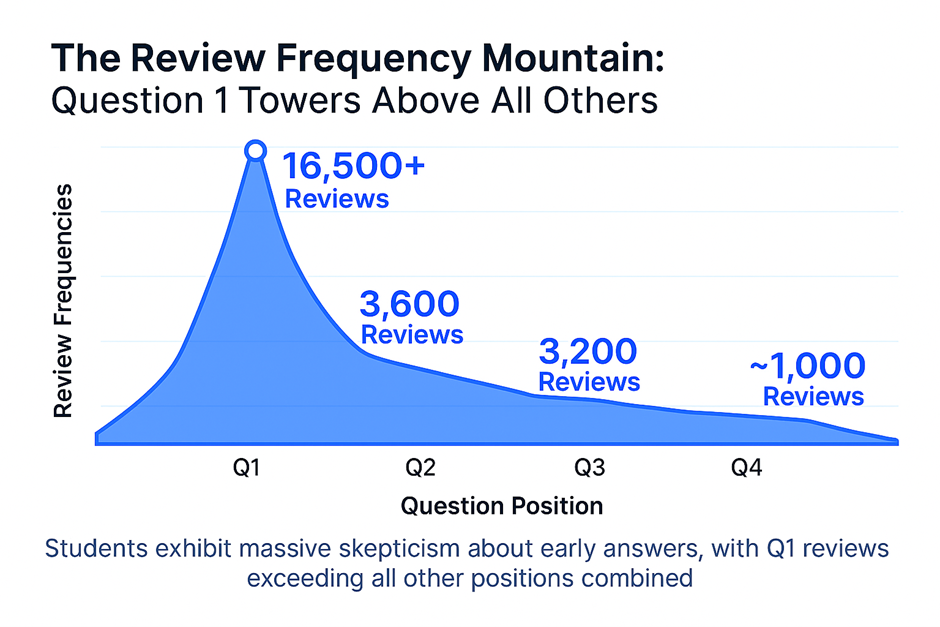
Pattern 1: Massive Early Skepticism and the Warm-Up Effect
The first pattern leaps from the data with unmistakable clarity: test-takers exhibit profound skepticism about their initial responses in early questions, creating what can only be described as a mathematical “warm-up effect.”
The numbers paint a vivid picture:
- Question 1: 16,500+ review instances—a towering peak that dwarfs every other position
- Questions 2-3: 3,600 and 3,200 instances respectively, still dramatically elevated
- Question 10+: Activity plummets to around 1,000 instances per position
This isn’t mere caution—it’s a psychological phenomenon. Test-takers fundamentally don’t trust their problem-solving abilities when starting fresh. The first question feels deceptively manageable, triggering a cascade of doubt: “This seems too straightforward. I must be missing something. Let me work through it again.”
⭐ Key Insight: Students exhibit the least confidence precisely when they’re often performing most effectively. This early skepticism reflects what psychologists recognize as a “cold start” problem—students haven’t yet calibrated to their mathematical performance level for that specific session.
What makes this pattern fascinating is that the skepticism often proves justified. As we’ll see, early-question review attempts succeed at remarkable rates, suggesting that students’ instincts about the value of double-checking are correct—at least initially.
Pattern 2: The Time Investment Profile – Reading the Algorithm’s Intentions
The time allocation data reveals not just how students spend their minutes, but where the adaptive algorithm begins to show its true nature.
Here’s the complete breakdown for Questions 1-9:
| Position | Initial Time | Review Time | Total | Algorithm Signal |
| 1 | 125 sec | 85 sec | 210 sec | Baseline difficulty |
| 2 | 105 sec | 75 sec | 180 sec | Still accessible |
| 3 | 95 sec | 65 sec | 160 sec | Confidence building |
| 4 | 100 sec | 70 sec | 170 sec | Stable performance |
| 5 | 105 sec | 80 sec | 185 sec | First adjustment |
| 6 | 160 sec | 85 sec | 245 sec | Difficulty spike begins |
| 7 | 150 sec | 80 sec | 230 sec | Algorithm probing upward |
| 8 | 145 sec | 75 sec | 220 sec | Ceiling search continues |
| 9 | 135 sec | 70 sec | 205 sec | Last manageable challenge |
Two critical patterns emerge that every test-taker should recognize:
- ⏱ The Q1-2 Investment Strategy: Students naturally invest an additional 75-85 seconds reviewing their first two responses. This represents nearly doubling their time commitment on early questions—and as we’ll discover, it’s a strategy that pays dividends.
- ⚠️ The Q6-8 Algorithm Warning: The dramatic spike in initial time (jumping from 105 to 160 seconds at position 6) signals that the adaptive algorithm has begun its upward calibration. If you’ve ever felt questions suddenly become more challenging around positions 6-8, the data confirms your intuition is exactly right.
This Q6-8 pattern serves as nature’s early warning system. Students who learn to recognize this difficulty escalation can prepare mentally for the transition from “review as helpful tool” to “review as questionable strategy.”
❓Want to Master GMAT Timing Patterns?
Understanding when the algorithm shifts difficulty is crucial for strategic preparation. Our adaptive practice platform helps you recognize these patterns and develop optimal timing strategies for each phase of the test.
Pattern 3: Early Success – The Mathematics of Productive Review
The most compelling case for strategic early review comes from analyzing what actually happens when students make changes in positions 1-8.
The results are remarkably consistent:
| Position | Wrong → Right | Wrong → Wrong | Right → Wrong | Success Rate |
| 1 | 12,000 | 3,000 | 1,500 | 73% productive |
| 2 | 2,500 | 800 | 300 | 69% productive |
| 3 | 2,200 | 700 | 300 | 69% productive |
| 4 | 1,800 | 600 | 250 | 68% productive |
| 5 | 1,500 | 500 | 200 | 68% productive |
| 6 | 1,200 | 400 | 150 | 69% productive |
| 7 | 1,000 | 350 | 150 | 67% productive |
| 8 | 900 | 300 | 100 | 69% productive |
✅ The pattern is striking: approximately 9 out of every 10 review attempts in early positions either improve the score (wrong-to-right) or maintain it (wrong-to-wrong). Only about 1 in 10 attempts actually damage performance through right-to-wrong changes.
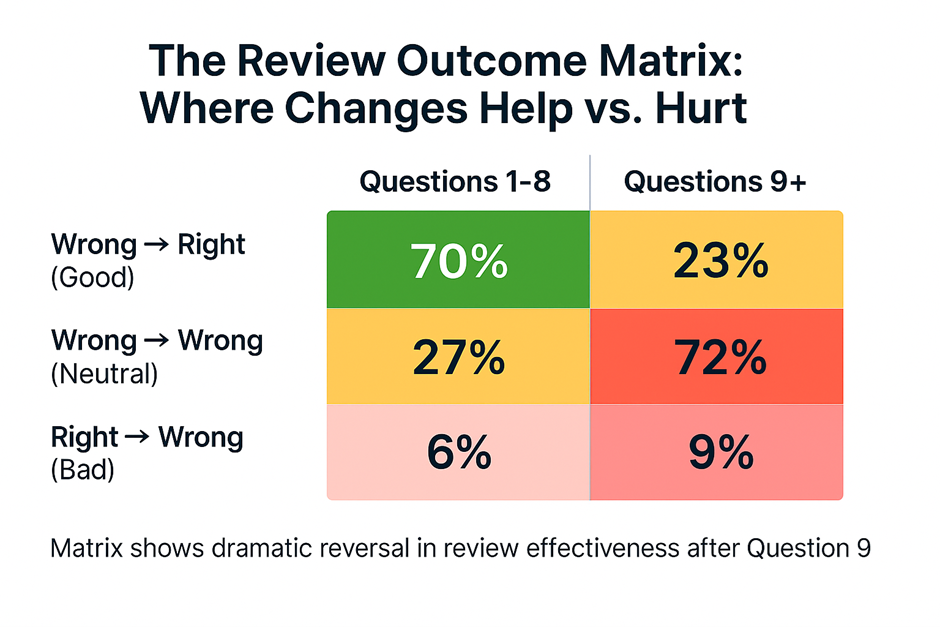
Position 1 deserves special recognition: with 12,000 wrong-to-right improvements against only 1,500 right-to-wrong errors, first-question review succeeds at an extraordinary rate. This explains why students intuitively invest so heavily in reviewing their opening response—their instincts about its value are mathematically sound.
The early-section pattern demolishes any argument that review represents mere neurotic behavior. Through Question 8, review constitutes a genuinely productive strategy with success rates that would make any investment advisor envious.
Pattern 4: The Q9+ Reality Check – When Mathematics Becomes Guesswork
The fourth pattern represents the most dramatic reversal in the entire analysis, and it’s where the story takes its crucial turn.
- Question 9 – The Inflection Point: For the first time, wrong-to-right changes become the minority, dropping to approximately 40% of all modifications. The tide has turned.
- Questions 10+ – The New Reality: The ratio completely inverts. For every 1 wrong-to-right improvement, there are now 3 wrong-to-wrong lateral moves. The success rate collapses to roughly 25%.

⚠️ Critical Finding: After Question 9, three out of four review attempts accomplish nothing positive. They don’t hurt your score (wrong-to-wrong changes are neutral), but they don’t help either.
More concerning are the right-to-wrong changes, which while still a minority, represent the only form of genuine score damage through review. Students who change correct answers to incorrect ones are literally subtracting points from their performance.
This transformation defies every intuition about problem-solving. The same analytical process that created value 70% of the time in early questions becomes essentially random after position 9. It’s as if the review feature has been rewired to work against mathematical logic.
The Timing Mystery: Why Question 9 Marks the Turning Point
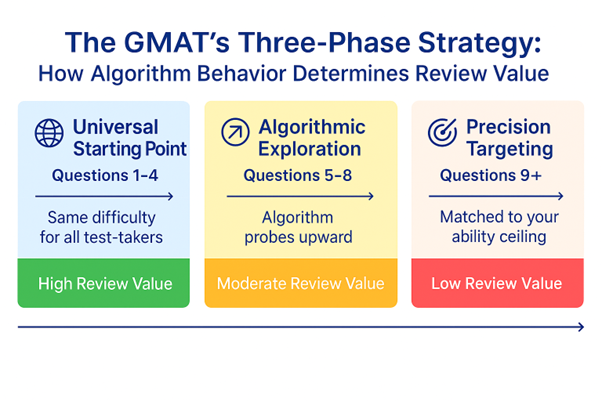
The dramatic effectiveness shift around Question 9 isn’t arbitrary—it’s the inevitable result of how the GMAT’s adaptive algorithm systematically discovers your mathematical capabilities. Understanding this timing requires grasping how the test transitions from assessment to precision targeting.
GMAT’s Three-Phase Calibration Strategy
Phase 1: Universal Starting Point (Questions 1-4)
Every test-taker begins with the same reality: medium-difficulty questions designed to establish baseline performance. Whether you’re a quantitative superstar or someone who breaks into a cold sweat at the mention of algebra, your first questions come from the same general difficulty pool.
This democratic starting point creates an environment where review naturally succeeds. Students with strong mathematical backgrounds face questions well within their comfort zones, providing cognitive surplus for productive second-pass analysis.
The algorithm prioritizes data collection over precision during this phase. It’s learning your problem-solving patterns, speed, and accuracy tendencies. Questions deliberately err on the side of being too easy rather than too hard, ensuring the algorithm gathers reliable performance data.
Phase 2: Algorithmic Exploration (Questions 5-8)
Armed with initial performance data, the algorithm begins its calibration dance. Strong early performers start seeing increased complexity, while those who struggled receive more accessible alternatives.
The Q6-8 difficulty spike our data revealed represents the algorithm’s “upward probe”—testing whether students can handle increased mathematical sophistication. Those dramatic initial time increases (jumping from 105 to 160 seconds at position 6) reflect students encountering their first algorithmic challenges.
This phase creates the perfect storm for effective review. Questions have increased in difficulty but remain within most students’ extended capability ranges. Students can feel the challenge escalating but still possess the mathematical resources to improve upon initial attempts through careful reconsideration.
Phase 3: Precision Targeting (Questions 9+)
By Question 9, the algorithm possesses sufficient data (8+ questions worth) to make confident assessments about individual mathematical ceilings. The exploration phase ends; precision targeting begins.
Questions 9+ are specifically calibrated to operate at your personal ability boundary. The algorithm has learned where your mathematical reasoning becomes uncertain, where your problem-solving speed slows, and where your accuracy begins to falter. It designs questions to test those precise limits.
This is where review effectiveness collapses catastrophically. Your initial response to ceiling-level questions already represents your maximum analytical effort under time pressure. There simply aren’t additional cognitive resources to deploy during review that weren’t already engaged in the first pass.
The Cognitive Science of Peak Performance
Why First Instincts Triumph at Your Mathematical Ceiling
When the GMAT presents questions matched to your ability ceiling, something fascinating happens neurologically. Your initial problem-solving attempt automatically engages every mathematical tool in your arsenal—pattern recognition, computational shortcuts, conceptual understanding, and strategic reasoning all activate simultaneously.
ℹ️ Cognitive Reality: Review attempts at ceiling level face an insurmountable limitation: they’re trying to improve upon a response that already utilized your peak mathematical capabilities. Unless you’ve made an obvious computational error (increasingly rare as questions become more conceptual), second-pass analysis typically substitutes correct reasoning with alternative approaches that feel more sophisticated but prove less accurate.
How Much Does Wrong-to-Right Actually Improve Your Score?
Understanding when review helps is only half the equation. The other critical piece is understanding how much different types of corrections actually impact your final score. The GMAT’s adaptive scoring algorithm doesn’t treat all correct answers equally—the scoring impact depends entirely on how the question’s difficulty compares to your demonstrated ability level.
This relationship explains why our data shows such dramatically different review effectiveness patterns between early and late questions. It’s not just about success rates—it’s about the magnitude of scoring impact when you do succeed.
High Impact Scenario: Fixing Below-Ability Mistakes
The Scoring Multiplier Effect
When you change a wrong answer to right on a question whose difficulty falls significantly below your demonstrated ability level, the scoring impact can be substantial—potentially worth multiple points on the 205-805 scale.
Here’s why: the GMAT’s Item Response Theory (IRT) scoring model heavily penalizes errors on “easy” questions relative to your ability. If you’re a 99th percentile test-taker who gets a easy question wrong, the algorithm interprets this as strong evidence that your true ability might be lower than initially estimated.
This scenario is most common in early questions for high performers:
- A 705-scorer fixes a careless error on Question 2: The question difficulty might be 550-level, making the correction worth 15-25 points
- A 655-scorer catches an early mistake on Question 4: If the question was 500-level, the correction could add 10-20 points
- The same scorer fixes Question 15: Since the question is likely to be closer to your true estimate, the correction might not add much.
This multiplicative effect explains why Position 1 reviews are so valuable for strong test-takers.
The Low Impact Scenario:
After Question 9, even successful wrong-to-right changes barely move the scoring needle. Why? By this point, the algorithm has calibrated questions to your exact ability level. You’re expected to get roughly half of these questions wrong. Changing one from wrong to right simply confirms what the algorithm already knows—you’re operating at your ceiling. The scoring impact shrinks to perhaps 1-2 points, making those review attempts mathematically inefficient.
The data bears this out: for every 1 wrong-to-right improvement after Question 9, you’re creating 3 wrong-to-wrong lateral moves. You’re spinning your wheels 75% of the time for minimal potential gain even when you do succeed.
↗️Apply This Strategy in Practice
Ready to implement the Q9 Protocol in your preparation? Practice with our adaptive mock tests and timing analytics to master when to review and when to trust your first instinct.
- Adaptive practice questions that mirror the algorithm’s behavior
- Detailed timing analytics to track your review effectiveness
- Strategic frameworks for optimal question sequence management
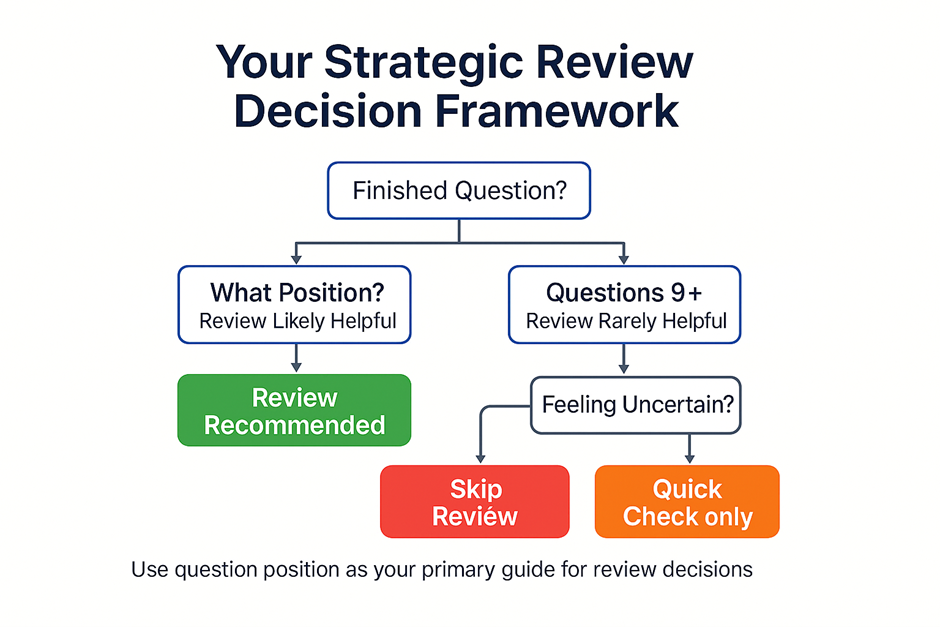
Bottom Line: The New Review Strategy
The data has spoken with remarkable clarity. Through Question 8, your review efforts succeed roughly 69% of the time. After Question 9, that success rate plummets to 25%. This isn’t a gradual decline—it’s a cliff.
⭐ Your New Review Strategy: When time remains after completing all 21 questions:
Return immediately to Questions 1-8
Invest most heavily in Questions 1-2 (where 73% of changes improve your answer)
Check Questions 3-8 for obvious errors only
Stop at Question 9—completely
The hardest part isn’t understanding this data—it’s trusting it.
Next time you practice, implement the Q9 Protocol: Review Questions 1-8 if time permits, then put your pencil down.
⭐ Master the Q9 Protocol Today
Transform your GMAT performance with data-driven review strategies:
- ✅ Adaptive mock tests that track your review effectiveness
- ✅ Timing analytics to identify your optimal review patterns
- ✅ Strategic frameworks for Questions 1-8 optimization
- ✅ Personalized coaching on when to trust your first instinct
- ✅ Advanced scoring algorithms that mirror the real GMAT